

Возможно, ваша компания захочет перейти на архитектуру микросервисов и автоматизировать рабочие процессы...

Узнайте, как Deutsche Telecom перешла от каскадной разработки монолитного приложения к гибкой архитектуре на основе микросервисов...
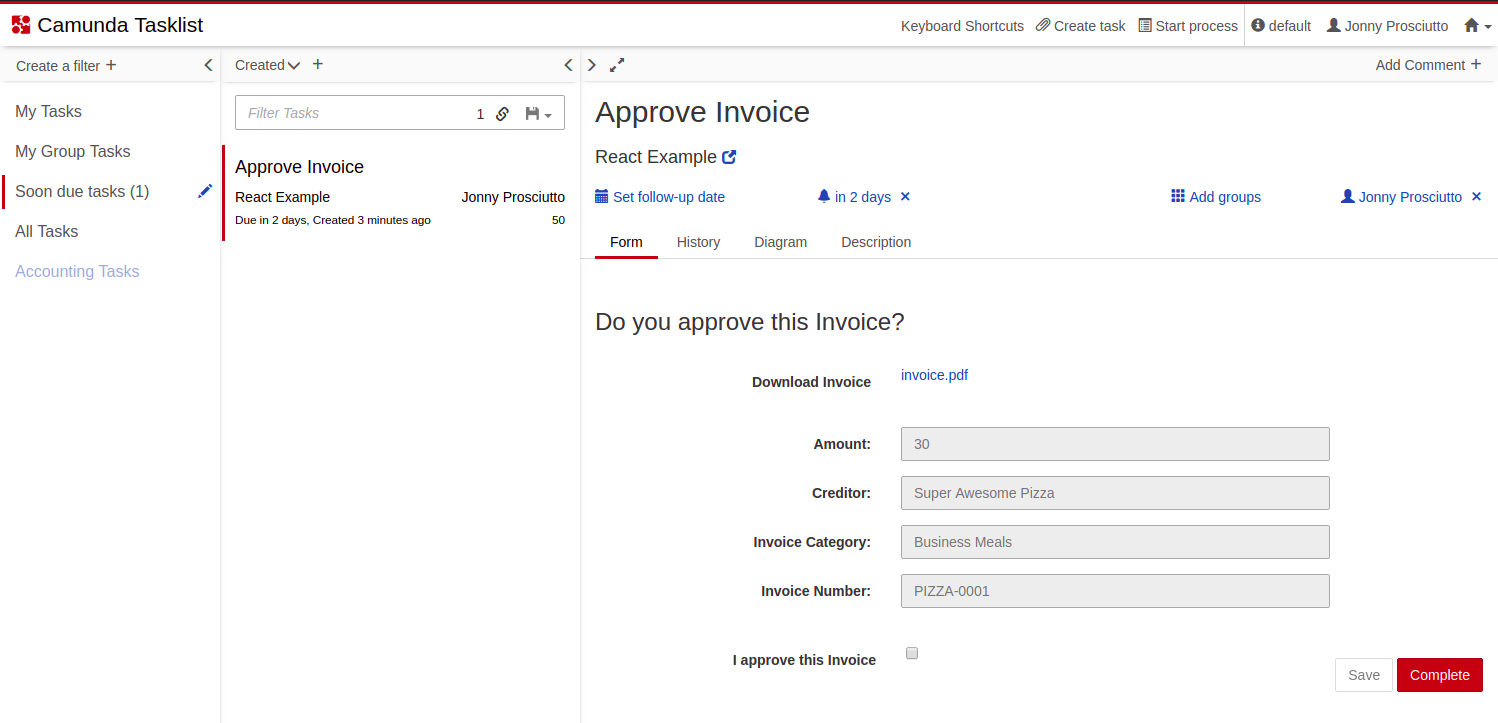
Список задач Camunda (Camunda Tasklist) отлично подходит, когда у вас есть пользовательские задачи и вы не хотите использовать или создавать собственное решение. Встроенные формы обеспечивают большую гибкость при проектировании пользовательских интерфейсов...
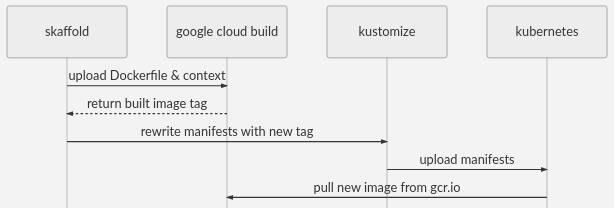 Используете Kubernetes? Готовы переместить свои экземпляры Camunda BPM с виртуальных машин, а может просто попробовать запустить их на Kubernetes? Давайте рассмотрим некоторые распространенные конфигурации и отдельные элементы, которые можно адаптировать к вашим конкретным потребностям...
Используете Kubernetes? Готовы переместить свои экземпляры Camunda BPM с виртуальных машин, а может просто попробовать запустить их на Kubernetes? Давайте рассмотрим некоторые распространенные конфигурации и отдельные элементы, которые можно адаптировать к вашим конкретным потребностям...

Если вы были частью сообщества Camunda некоторое время, вы, вероятно, взаимодействовали с Найлом, Маурицио или Джошем на форумах Camunda и Zeebe. Но знаете ли вы, что все они являются частью большого отдела по связям с разработчиками (Developer Relations = DevRel) в Camunda?...
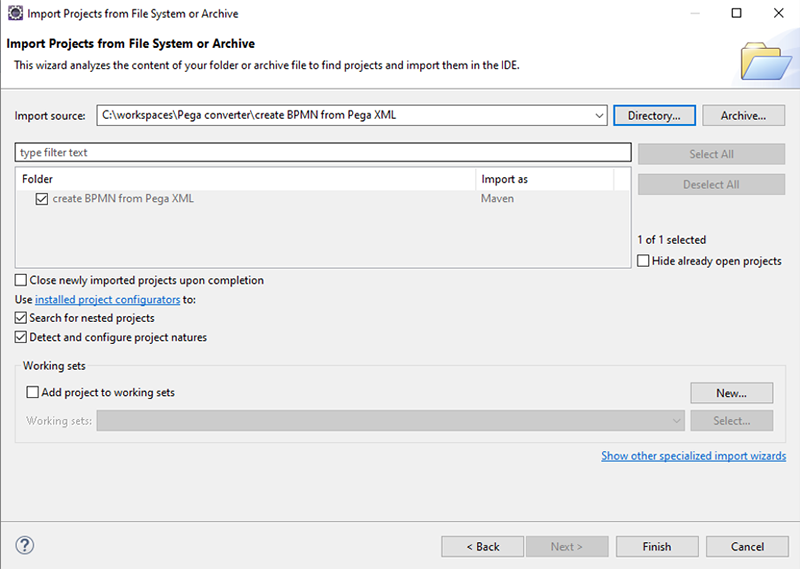 Известно, что процессные потоки, созданные в Pega, не соответствуют ни одному открытому стандарту, несмотря на то, что выглядят скорее как BPMN-образцы. Люди, которые хотят перепрыгнуть, начинают свою миграцию с Pega на Camunda с того, что вручную перерисовывают процессы в Modeler. Но ручное перерисовывание процессных потоков утомительно и занимает много времени...
Известно, что процессные потоки, созданные в Pega, не соответствуют ни одному открытому стандарту, несмотря на то, что выглядят скорее как BPMN-образцы. Люди, которые хотят перепрыгнуть, начинают свою миграцию с Pega на Camunda с того, что вручную перерисовывают процессы в Modeler. Но ручное перерисовывание процессных потоков утомительно и занимает много времени...